
Bézier polynomial curve regression
Sharks. I never saw that coming.
Ask NotebookLMIntroduction
How often have you said to yourself, “Gosh, I sure wish I knew an easy way to approximate a curve with an th-degree Bézier polynomial!” Several times a day would be my guess. Well, there is a way! In fact, just a little bit of linear algebra, orthogonal distance regression, and the Akaike criterion is about all you need. The linear algebra gives us a starting guess, orthogonal distance regression refines the control points by letting the curve slide its closest points onto the data, and the Akaike criterion tells us how many control points are actually worth keeping.
What is this stuff? It’s a way to describe how smooth a function or curve is. Smoothness depends on continuity and differentiability. It’s often possible to look at the plot of a function and see that it’s at least . If the function is continuous and doesn’t have any sharp bends anywhere, you’ve probably got a or higher function. The functions we’ll study will be like this, that is, without corners and are continuous everywhere. The background section near the end of the article gives the precise definitions, and we’ll confirm that the fitted Bézier result inherits this smoothness.
Why Bézier polynomials? The advantage is that using only a few control points, the entire curve can be defined. Instead of using hundreds of points along the curve, you can generate the same curve from a handful of control points, and the Akaike criterion will tell how many of these control points are needed.
Bézier curves are derived from Bernstein polynomials, but were not applied until Paul de Casteljau derived a numerically stable method now called de Casteljau’s algorithm which he used for computer aided design at the French automaker Citroën. Pierre Bézier independently discovered the polynomials and used them to design car bodies at Renault. We used Bézier curves in Yacht Design with Mathematics. My interest in the inverse problem that is, recovering control points from curve data, started with a 2002 paper by Borges and Pastva.
Bézier curves are now applied in illustrator programs like Adobe Illustrator and Inkscape, in font design, in many Computer-Aided Design (CAD) software programs, and for robotics path planning. By manipulating the locations of the control points, you can quickly modify the shape of the resulting curve. The more difficult inverse problem, which we’ll solve here, is to reconstruct the locations of the control points from a given curve.
Program Outline
The Julia file BezierCurveFit.jl fits Bézier polynomials to a set of points describing the curve to be fit. The polynomials are parameterized by , so that for some polynomial at . Similarly, . Since we don’t know the values for , our first task is to estimate them from the measured points in but, as we’ll see, if the aren’t known, we won’t get a good fit. The real trick is to stop treating as known. Instead of guessing and then solving for the control points, we let an optimizer adjust both the control points and the values at the same time. That joint optimization is called orthogonal distance regression (ODR) Orthogonal distance regression minimizes the perpendicular (shortest) distance from each data point to the fitted curve, rather than the vertical distance minimized by ordinary least squares. When data points can have errors in both and — as digitized curve points do — perpendicular distance is the geometrically correct thing to minimize., and it’s what turns a mediocre fit into a good one.
The curve points in can be found by multiplying a matrix of coefficients, , and the control points , . The inverse also works, so , (using some special tricks described below). To create , we need to know how many control points there are, and we need to generate the Vandermonde matrix from .
If we knew exactly, we could perfectly generate , and we’d know where the control points were. Errors in our estimate of cause fairly large errors when we calculate the estimated control points, , and consequently errors in locations of the estimated curve points, . The points in are interpolated to the nearest approximation of points in .
Using some optimization techniques, we can iterate on the estimates of the locations of the control points until the error between and is as small as is computationally possible. Critically, we let the parameter values move during this iteration too. Each slides until arrives on the point of the curve closest to the measured . Minimizing that perpendicular (geometric) distance, rather than the distance at a fixed, and possibly wrong , is the defining feature of orthogonal distance regression.
In most cases, the curve points weren’t generated using Bézier polynomials, so the approximating polynomials in this process depend on the number and locations of the control points . Starting with a small number of control points, we can use this procedure to get , then increase the number of control points to generate a new , repeating until the fit is good enough. “Good enough” is exactly the judgment the Akaike criterion The Akaike Information Criterion (AIC) was introduced by statistician Hirotugu Akaike in 1974. It balances model fit against complexity by adding a penalty proportional to the number of free parameters — the mathematical formalization of Occam’s Razor. Lower AIC is better; what matters is differences in AIC between models, not the absolute value. automates. More control points always reduce the residual error, so we need a penalty that punishes extra parameters and stops us from overfitting.
The outline for the curve fitting function is:
- Read in measured curve points (an array from WebPlotDigitizer, described below).
- Estimate the parameter vector from the distances between successive points in (the chord length).
chord_length_param(Q)t. - Construct the Bernstein basis matrix .
bernstein_matrix(t, m)A(m= degree, so hasm+1columns). - Warm-start the control points by endpoint-constrained least squares.
init_control_points(Q, t, m)P. - Jointly optimize
Pandtby orthogonal distance regression.fit_bezier_odr(Q, m)P_fit, t_fit. - Select the best degree by residual-elbow detection (with AIC fallback).
select_degree_robust(Q)m_best, P_best. - Optionally enforce a monotone parameterization.
monotone_reproject(Q, P_fit)t_monotone.
The first half of this article builds up the linear algebra behind bernstein_matrix and init_control_points; the second half explains the orthogonal distance regression in fit_bezier_odr, the degree selection in select_degree_robust, and the reprojection in monotone_reproject.
Bézier Polynomials
In the article Yacht Design with Mathematics we used Bézier polynomials to approximate the curves of a boat hull. The Bézier polynomial is defined as
The array represents the locations of control points and can have any coordinates you like. Notice that the index starts at which is why there are rather than control points. (In the code sections later, we follow the Julia convention and call the degree , so the curve has control points — the math here uses to keep the standard textbook notation.) The parameter goes between and , and the symbol
is the binomial coefficient, and is factorial. The binomial coefficient tells how many ways you can choose things from a set of , and it also gives the coefficients in the expansion of . You can check the expansion coefficients by typing
expand((x+y)^4)
and checking that the same coefficients appear in the vector,
n = 4
[binomial(n,k) for k = 0:n]'
[1, 4, 6, 4, 1]when you run it in Julia. You could have gotten each coefficient by typing binomial(4,0), binomial(4,1), …, binomial(4,4), but the notation above is a shortcut to generate them all at once, called list comprehension.
Another way to get the coefficients is to use Pascal’s Triangle. Each row represents the th set of expansion coefficients. The zeroth row is the single at the top, so the expansion for is the fifth row down, . If you want to explore more about Pascal’s Triangle, read Zaphod Beeblebrox’s Brain and the Fifty-ninth row of Pascal’s Triangle by Andrew Granville.

Pascal’s Triangle.
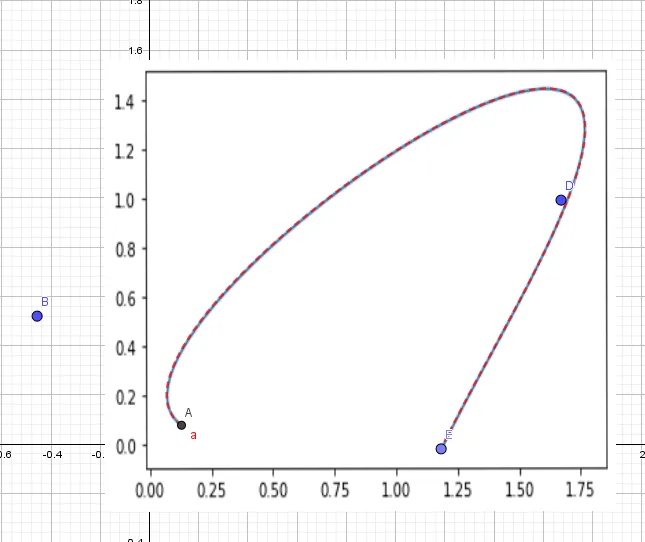
The location of the points controls the shape of the curve. Here’s a curve created with five control points that looks a little like a shark fin drawn with GeoGebra. Notice that the control points are not in order. Place five points anywhere on the canvas, and then type
curve[x(A)*(1−t)^4+4*x(B)*(1−t)^3*t+6*x(C)*(1−t)^2*t^2+4*x(D)*(1−t)*t^3+x(E)*t^4,y(A)*(1−t)^4+4*y(B)*(1−t)^3*t+6*y(C)*(1−t)^2*t^2+4*y(D)*(1−t)*t^3+y(E)*t^4,t,0,1]
in the Input: dialog box.
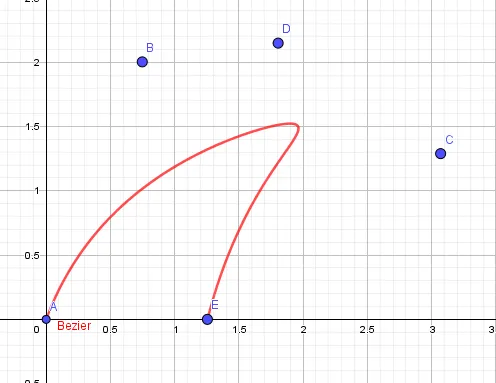
Bézier-generated shark fin in GeoGebra.
You can find any point on the curve by varying between and , and using the formula for above. You can do this in a spreadsheet:
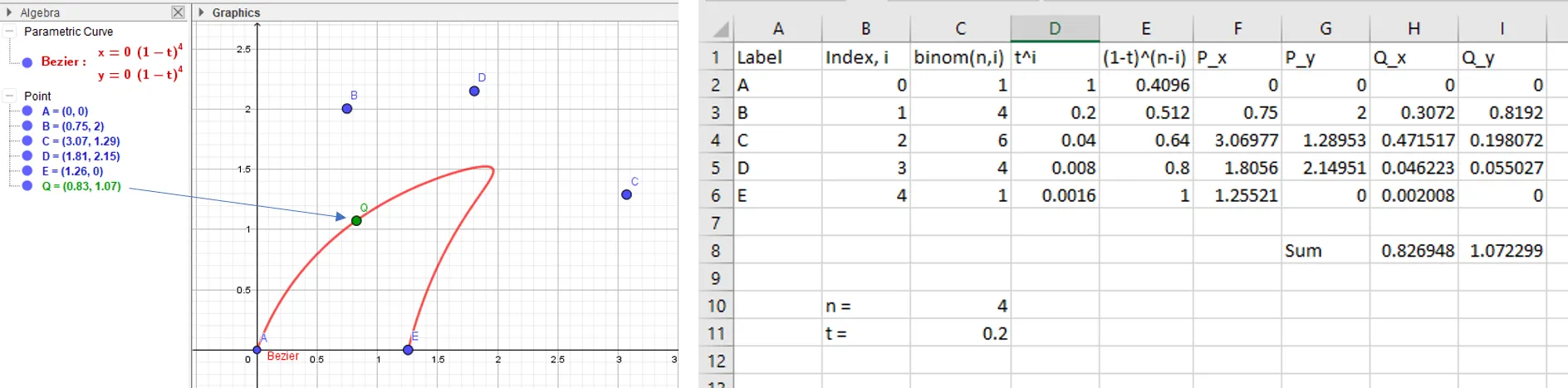
Spreadsheet calculations for the Bézier curve.
In the first column of the spreadsheet I entered the point labels and in the next column is the index, , running from to . Below the main table, I entered two labeled cells, and . The value for should be one less than the number of points since indexing begins at zero. You can put any value for so long as it’s in the range . The third column is the binomial expansion coefficient for and . Excel uses =combin(n,a2).
The third and fourth columns, “D” and “E” contain the powers of and . In the next two columns, put in the coordinates for each of the five points. Right click on point A and click on “Object Properties” to open a window on the right side of GeoGebra. Under the “Basic” tab you should see the name of the point and the value. Copy the values for the and coordinates into the columns labelled P_x and P_y in the spreadsheet. If you’ve put point A at the origin, GeoGebra will have Definition: Intersect(xAxis, yAxis), but just enter zeros.
Any number raised to the power is , but Excel incorrectly assumes the answer is undefined. If this happens with your spreadsheet, replace the cells with ‘s. In the example, this would be in cells D2 and E6. Or, you could use the open-source LibreOffice suite which correctly calculates zero powers.
Using the formula,
we can calculate Q_x and Q_y for each point, which are the products of columns C,D,E, and F for Q_x and C,D,E, and G for Q_y. Then, sum the columns to get the coordinates for . In GeoGebra, add a new point and rename it . Right click on “Q” and enter the calculated coordinates in the Value box. It should fall somewhere on the shark fin plot. If you change the value of in the spreadsheet, you’ll get a new position for somewhere on the plot.
After choosing the locations for control points , and you can generate the shark fin curve by varying the value of between and .
Bézier Linear Algebra
Let’s look at again,
Suppose we have control points, , so since the index begins at zero. If we write out the terms of we get
Each row of the matrix is binomial expansion of . Both and are used here for element-wise (Hadamard) multiplication of two matrices with the same dimensions — the distinction in what follows is purely structural: multiplies two full matrices entry-by-entry, while broadcasts a column vector across all columns of a matrix (the Julia dot-broadcast operation). The sign matrix with alternating ‘s changes every other sign of the values in the matrix . The binomial expansion multiplies each column of by the appropriate coefficient, and is the first row of , denoted by . Multiplying the coefficient matrices together gives
Since we know how many control points there are, we can quickly create the coefficient matrix . Multiply the control points array by the coefficient matrix to get
The last step is to create the vector of values between and using the Julia range function:
t = range(0, 1, num = nPts)Setting nPts = 100 gives 100 points along the curve. For each value of we need , which is a Vandermonde matrix, but flipped left and right. For any input vector , with exponents up to , this code returns the Vandermonde matrix, , which has size :
VM = Matrix{Float64}(undef, length(v), n + 1);
for k in 0:n
VM[:, k + 1] = v .^ (n - k)
endThe Bézier curve points can be found by multiplying , which will be . The first column contains the -coordinates and the second the -coordinates. To check that the math is correct, I plotted the Bézier curve of the shark fin in Julia and then overlaid it onto the GeoGebra curve. The red dashed line is the curve generated by GeoGebra, and the solid blue is the Julia curve.
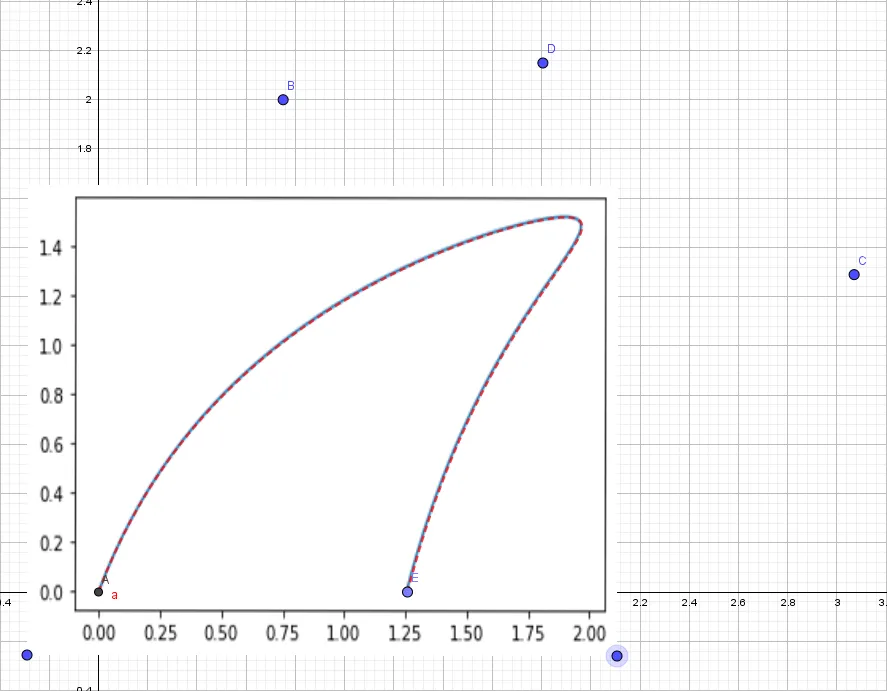
Original shark-fin curve with GeoGebra overlay.
But, suppose you had the plot already, and wanted to know where the control points should be placed to reproduce the curve? We’d like to be able to reverse the process to get the control points.
Curve point coordinates
To get the coordinates of the curve points in GeoGebra first turn off extraneous points. On the left side of the window, under Algebra is a list of the control points with small dots to the left of the label. Click on each one to hide the point in the graph. Save the graph as an image using File Export Graphics View as Picture (png, eps).
Now, go to the WebPlotDigitizer site and click on Launch Now! Under File select Load Image(s) and Browse to find your image of the curve. The default type is 2D (X,Y) Plot which is right for our plot. Click Align Axes at the bottom and Proceed on the next pop-up window. Click on a known -coordinate somewhere on the left side and then a second known coordinate to the right. Repeat this for two known -coordinates. You can use the origin for both if you like. If you need to adjust points, click on the point and use the arrow keys to move it. When the points are in the correct positions, click on Complete! The next dialog asks for the coordinates of these points.
Under Automatic Extraction, click on the blue square to the right of Foreground Color, then choose Color Picker and click on a point of the curve, then Done. Click Run and you should see points that WebPlotDigitizer has selected along the curve. If any points don’t seem to be on the curve, click Adjust Point (S) and use the arrow keys to move them back onto the curve.
On the left side under Dataset click View Data, Sort by: Nearest Neighbor and then Download .CSV. The Nearest Neighbor sorting option puts the points in order along the length of the curve. Name the file something like SharkFinCurve.csv and save it. Open the file with a text editor such as Notepad++. Bézier polynomials go through the first and last control points exactly, so if WebPlotDigitizer didn’t pick up these points, add them in to the list of curve points. Do this by entering and in the spreadsheet and copying the summed values for Q_x and Q_y for each.
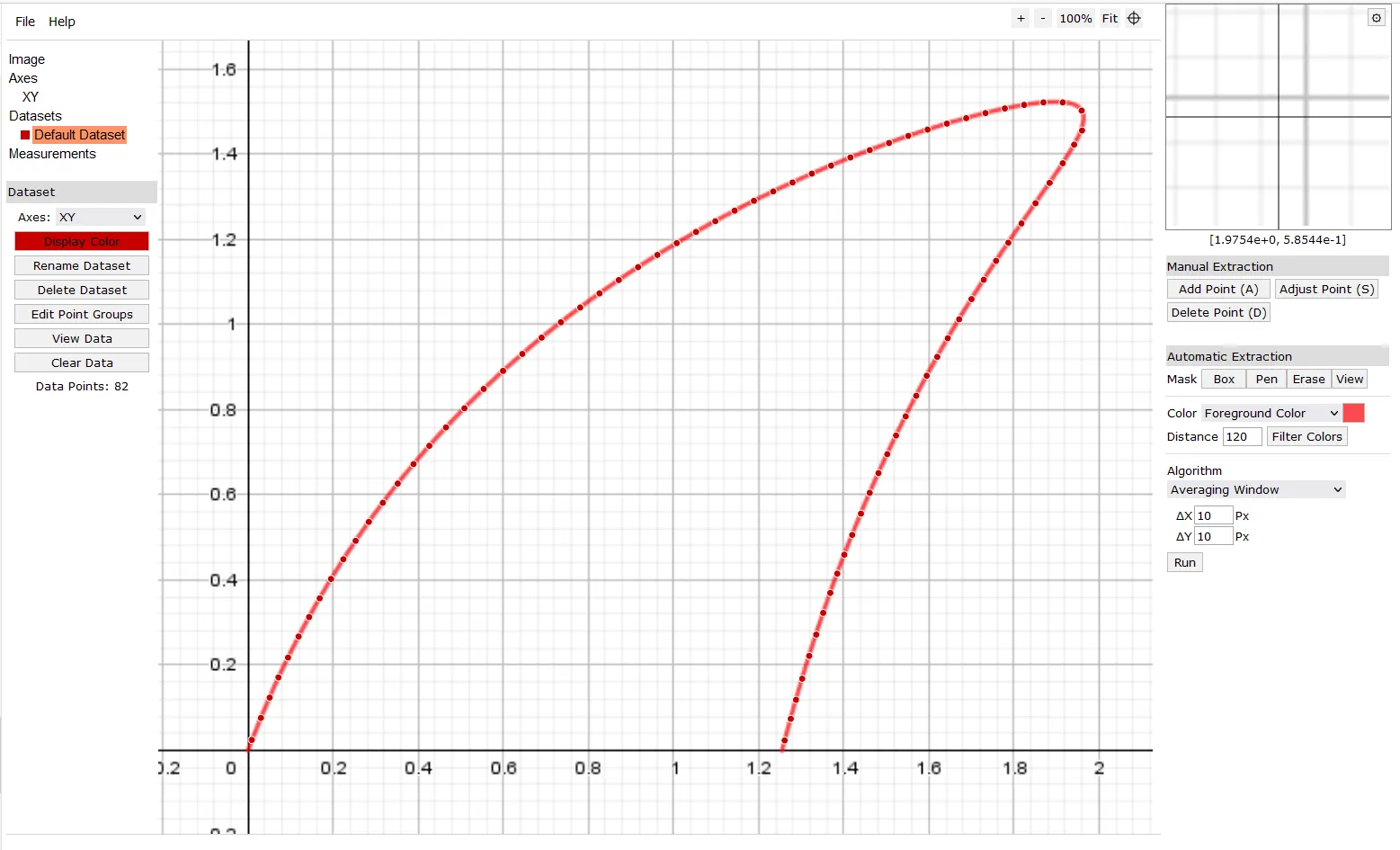
Extracting curve points using WebPlotDigitizer.
Finding the Control Points
The equation for the Bézier polynomial is the sum of coefficients times the control point coordinates. We could write it as
A more compact way to write it would be as the multiplication of two vectors (multiply corresponding entries, sum the whole thing),
If we use the result is the point . We could do this multiplication for many different values of along the curve and get the matrix multiplication,
In the example, there are five control points and WebPlotDigitizer generated steps along the curve. The matrix on the left is rows by columns, and the vector of ‘s is points long.
Compactifying a bit more, we can write this system of equations as where is the matrix of coefficients on the left, is the vector of control points, and is the vector of measured points along the curve. We need to find a vector that makes the difference between the estimated points and the measured points as small as possible. That is, we want to minimize the error , but it’s slightly more convenient to minimize the square, which gives another solution.
If we expand the square we get
recalling that for compatible matrices. To minimize the error we can take the derivative, and set the result to zero,
The solution for is simply,
In Julia, the numerically stable way to evaluate this least-squares solution is the backslash operator, which avoids forming and inverting explicitly:
P = bernstein_matrix(t, m) \ Qso you just need to get and then the calculation is easy. There’s a minor flaw with this method, though. The points along the curve seem to be uniformly spaced, but that doesn’t mean the values of are. We don’t know what should be for each , but we know that and , so we could calculate the cumulative distance along the curve and normalize by the total length to get approximate values for each Keep this flaw in mind — it’s the whole reason we’ll need orthogonal distance regression. The least-squares solution here isn’t our final answer; it’s a warm start that gets the optimizer into the right neighborhood.
Building the A matrix
The “Bézier Linear Algebra” section above expanded the basis into monomials — a coefficient matrix times a Vandermonde matrix in — which is great for seeing where the binomial coefficients come from. In code, though, it’s both shorter and numerically safer to evaluate the Bernstein basis directly from its definition,
where is the polynomial degree (the same thing the math above called ), so there are control points. This is exactly bernstein_matrix in BezierCurveFit.jl:
function bernstein_matrix(t::AbstractVector{Float64}, m::Int)::Matrix{Float64}
n = length(t)
B = zeros(Float64, n, m + 1)
for j = 0:m
c = binomial(m, j)
for i = 1:n
B[i, j + 1] = c * (t[i]^j) * ((1.0 - t[i])^(m - j))
end
end
return B
endFrom here on I’ll switch to the code’s convention: m is the degree, and the curve has m + 1 control points. The returned matrix is — one row per measured point, one column per control point — and evaluating the curve is then just the matrix product bernstein_matrix(t, m) * P, which is what the helper bezier_eval does.
We still don’t know the true values for , though. The simplest guess is to space them evenly between and , but a better guess measures the distances between the points in , the array returned by WebPlotDigitizer:
function chord_length_param(Q::Matrix{Float64})::Vector{Float64}
n = size(Q, 1)
d = [norm(Q[i+1, :] - Q[i, :]) for i in 1:(n-1)]
s = cumsum([0.0; d])
return s ./ s[end]
endThis is the chord-length parameterization The chord-length parameterization assigns values proportional to the cumulative straight-line (chord) distances between successive data points, as a proxy for arc length. It distributes parameter values roughly uniformly along the curve, avoiding the clustering that would result from spacing evenly when the data points themselves are unevenly spaced.. Each d[i] is the Euclidean distance between successive points in ,
The cumulative sum s is the running arc length with a prepended, and dividing by the total length s[end] normalizes everything into with and .
The result is:
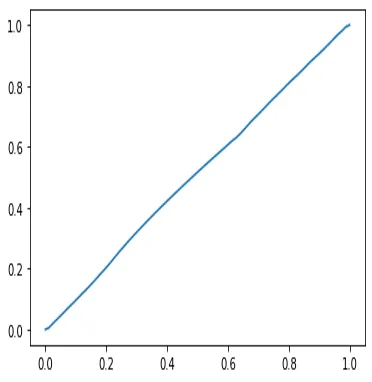
Estimated values of parameter .
There’s very little difference between even spacing and chord length for densely sampled curves. Using the basis matrix at these estimated values, we can take a first stab at the control points with an ordinary least-squares solution, and reconstruct the curve from them:
A = bernstein_matrix(t, m) # n × (m+1)
P_est = A \ Q # least-squares solve, (m+1) × 2
Q_est = A * P_estJulia’s backslash operator \ solves the overdetermined system in the least-squares sense. Plotting the estimated curve points gives a result that is not very shark-fin-ish:
The reconstructed curve doesn’t match the original.
The problem is that even small errors in the estimates of for each of the measured points in can result in large errors in the estimated control points .
| P_x | P_y | P_x (est) | P_y (est) | |
|---|---|---|---|---|
| 0 | 0 | 0.129955 | 0.076279 | |
| 0.75 | 2 | -0.45652 | 0.5199 | |
| 3.06977 | 1.28953 | 3.100084 | 2.820746 | |
| 1.8056 | 2.14951 | 1.671738 | 0.991036 | |
| 1.25521 | 0 | 1.184665 | -0.01976 |
But, notice that the blue curve generated from the estimated control points overlays the fit generated by GeoGebra, which uses a different vector from the one our least-squares solve used. The implication is that we should be able to match the original shark-fin curve if we can somehow maneuver the control points into place and, just as importantly, let the values move too.
A better warm start with endpoint-constrained least squares
Before handing the problem to an optimizer, we can do better than the raw least-squares solution. A Bézier curve passes exactly through its first and last control points, and we already know where the curve starts and ends — those are just the first and last measured points, and . So we can fix and and solve the least-squares problem for only the interior control points. The function init_control_points does this:
function init_control_points(Q::Matrix{Float64}, t::Vector{Float64}, m::Int)::Matrix{Float64}
if m == 1
return [Q[1, :]'; Q[end, :]']
end
A = bernstein_matrix(t, m) # (n, m+1)
A_fixed = A[:, [1, m+1]] # endpoint basis columns
A_free = A[:, 2:m] # interior basis columns (n, m-1)
rhs = Q - A_fixed * Q[[1,end], :] # subtract fixed contributions
P_free = A_free \ rhs # (m-1, 2), overdetermined LS
return vcat(Q[[1],:], P_free, Q[[end],:])
endThe trick is to move the known endpoint contributions to the right-hand side. We split the basis matrix into its two endpoint columns A_fixed and its interior columns A_free. The endpoints contribute A_fixed * [Q₁; Qₙ] to every fitted point, so we subtract that off and solve A_free \ rhs for the interior points alone. Stacking the fixed endpoints back around the solved interior points gives an control-point matrix that already honors the endpoints and sits close to the right answer. This is the warm start, and now we’ll refine it.
Orthogonal Distance Regression
Ordinary least squares minimizes
with the held fixed at whatever we guessed. The trouble, as the table above showed, is that a wrong drags the control points to the wrong place. Orthogonal distance regression (ODR) fixes this by minimizing over the control points and the parameter values at the same time,
subject to the endpoint constraints , , , and . Because each interior is now free to move, at the optimum lands on the point of the curve closest to . The residual we minimize is therefore the perpendicular, or geometric, distance from each data point to the curve which is exactly the closest-point problem we’ll work out by hand in the next section. ODR does it for us, for every point, on every iteration.
The Julia package Odrpack.jl wraps the Fortran ODRPACK95 solver, whose engine is a trust-region Levenberg–Marquardt minimizer designed for exactly this problem (Zwolak, Boggs & Watson, Algorithm 869, ACM TOMS 33(4), 2007). It minimizes the general weighted form
Here holds the model parameters (our flattened control points), is the explanatory variable (our parameter vector ), is the response (our data ), and is the adjustment the solver makes to each . The weight penalizes moving ; driving it toward zero makes effectively free and recovers pure geometric distance. Setting it to exactly zero is numerically degenerate in ODRPACK95, so the code uses a tiny value, making the parameters effectively free, while keeping the solver well-conditioned.
ODRPACK calls a model function with the signature f!(x, beta, y) that writes the curve points into y in place. Ours just reshapes beta into control points and evaluates the curve:
function bezier_fcn!(x::AbstractVector{Float64},
beta::Vector{Float64},
y::Matrix{Float64})
y .= bezier_eval(x, beta_to_P(beta))
return nothing
endThe control points live in beta as an interleaved vector , so we convert back and forth with a reshape:
beta_to_P(beta) = Matrix(reshape(beta, 2, :)') # interleaved vector → (p × 2)
P_to_beta(P) = vec(P') # (p × 2) → interleaved vectorPutting the warm start, the constraints, and the model together gives fit_bezier_odr:
function fit_bezier_odr(Q::Matrix{Float64}, m::Int;
tol::Float64=1e-10,
reproject::Bool=false)
n = size(Q, 1)
t_init = chord_length_param(Q)
P_init = init_control_points(Q, t_init, m)
beta_init = P_to_beta(P_init)
fix_b = falses(length(beta_init))
fix_b[1:2] .= true # fix P₀ = Q[1,:]
fix_b[end-1:end] .= true # fix Pₘ = Q[end,:]
fix_x_arr = falses(n)
fix_x_arr[1] = true # fix t₁ = 0
fix_x_arr[end] = true # fix tₙ = 1
result = odr_fit(
bezier_fcn!,
t_init,
Q,
beta_init;
fix_beta=fix_b,
fix_x=fix_x_arr,
jac_beta! = bezier_jac_beta!,
jac_x! = bezier_jac_x!,
weight_x = fill(1e-10, n)
)
P_fit = beta_to_P(result.beta)
t_fit = vec(result.xplusd)
if reproject
t_fit = monotone_reproject(Q, P_fit; tol=tol)
end
return P_fit, t_fit, result
endThe fix_beta mask freezes the first and last control points; fix_x freezes the first and last values at and . Everything else, the interior control points and every interior is free to move. The optimized parameter values come back as result.xplusd (the initial x plus the fitted adjustments ).
Analytic Jacobians
We could let ODRPACK estimate the derivatives by finite differences, but the Bernstein basis has analytic derivatives, so supplying them is faster and more accurate. The curve is linear in the control points, so the Jacobian with respect to is just the basis itself. Each coordinate of the output depends only on the matching coordinate of each control point, which is why the entries land on alternating slots:
function bezier_jac_beta!(x, beta, jb)
m = (length(beta) ÷ 2) - 1
n = length(x)
B = bernstein_matrix(x, m)
fill!(jb, 0.0)
for j in 1:(m + 1)
for i in 1:n
jb[i, 2*j - 1, 1] = B[i, j]
jb[i, 2*j, 2] = B[i, j]
end
end
return nothing
endThe Jacobian with respect to needs the derivative of the curve, which uses the derivative of the Bernstein basis,
with the convention and . That recurrence is bernstein_deriv, and bezier_jac_x! multiplies it by the control points to get at each point. With both Jacobians supplied, the solver recovers control points that put the curve right on top of the data, because the optimizer now has the freedom to slide the parameter values into place.
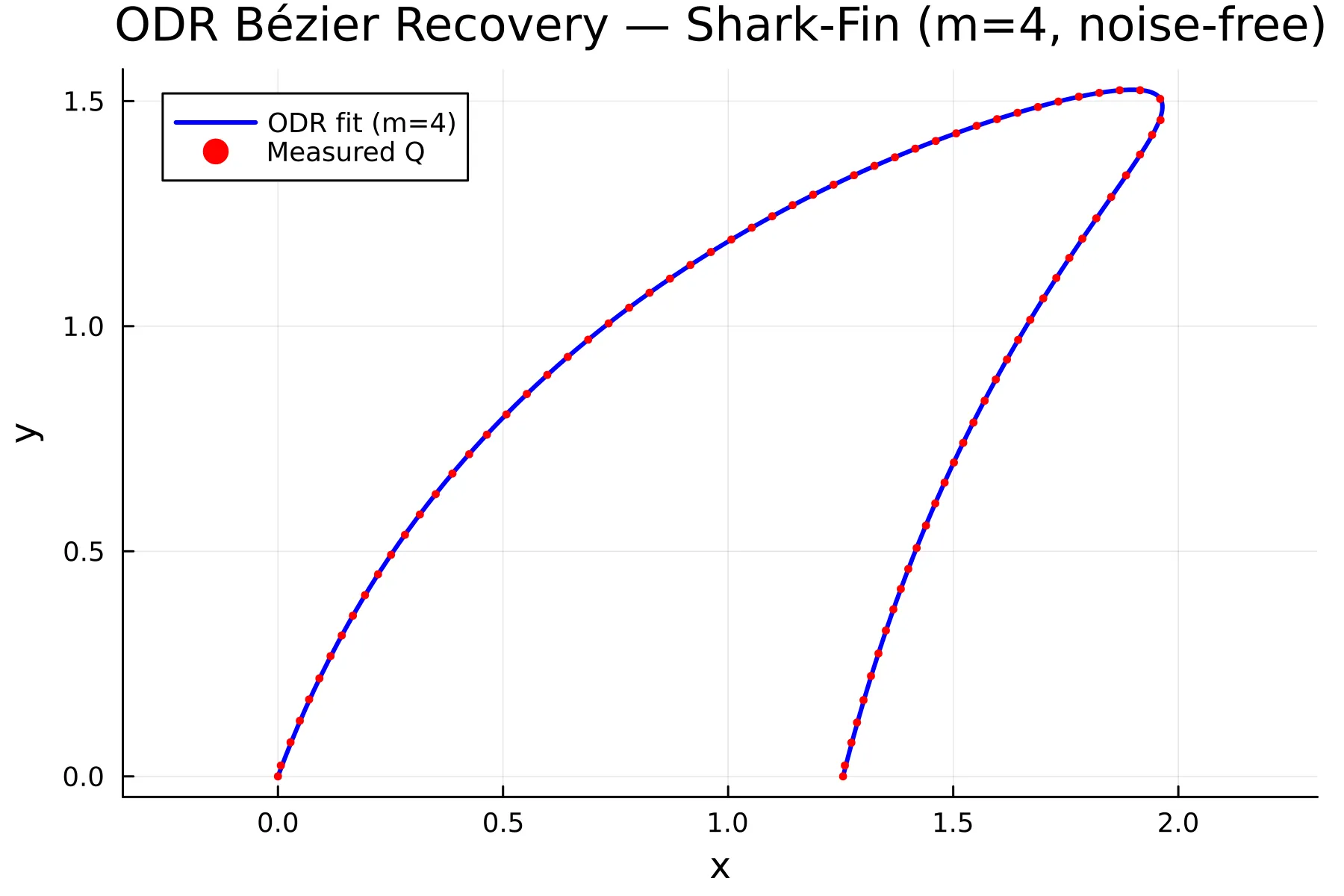
ODR-fitted Bézier curve () overlaid on the shark-fin data. The maximum geometric residual is 0.0025 — roughly 58× smaller than the degree-3 fit.
Choosing the Degree
We’ve been assuming we know how many control points to use, but in practice we won’t. Adding control points (raising the degree ) can only lower the residual error, and a high enough degree will fit the curve through every measured point even if it’s noisy. This is called overfitting, and looking at the residual error alone will never tell you that the curve has been over fit. We need a score that rewards a good fit but penalizes extra parameters.
Degree selection with AIC
The Akaike Information Criterion (AIC) gives this score for good fits,
where is the number of free parameters and is the maximized likelihood. For a model with Gaussian residuals and unknown
variance, the log-likelihood term reduces to plus a constant (after profiling out the variance), where SSE is the sum of
squared residuals. The constant is the same for every degree, so it drops out of the comparison, leaving the form select_degree_aic uses:
A degree- curve has control points, but the two endpoints are fixed, leaving free interior control points. Each has an and a coordinate, so there are free parameters, and the penalty is , which is the final term above. We pick the degree with the lowest AIC:
function select_degree_aic(Q::Matrix{Float64};
m_min::Int=2, m_max::Int=8,
tol::Float64=1e-10)
n = size(Q, 1)
m_range = m_min : min(m_max, n-2)
aic = Dict{Int,Float64}()
best_aic = Inf
m_best = m_min
P_best = zeros(0, 2)
t_best = zeros(0)
for m in m_range
P_fit, t_fit, _ = fit_bezier_odr(Q, m; tol=tol)
SSE = sum((bezier_eval(t_fit, P_fit) .- Q).^2)
aic[m] = n * log(max(SSE, eps()) / n) + 4*(m-1)
if aic[m] < best_aic
best_aic = aic[m]
m_best = m
P_best = P_fit
t_best = t_fit
end
end
return m_best, P_best, t_best, aic
endThe loop fits every degree from up to by ODR, computes the SSE at the fitted parameters, scores it, and keeps the
best. The max(SSE, eps()) guard keeps the logarithm finite if a fit is essentially perfect.
Note the specific form of the penalty: a degree- curve has control points, but the two endpoints are fixed, leaving free interior control points. Each has an and a coordinate, so there are free parameters, and substituting into the standard penalty gives , the final term in the formula above.
There are three further caveats worth keeping in mind:
- The latent values aren’t counted as parameters. ODR estimates interior alongside the control points, which could be thought of as additional degrees of freedom. The usual defense is that they are nuisance parameters bound one-to-one to the data points rather than free model structure, so they don’t inflate model complexity the way control points do.
- No term for the variance parameter. Strictly, estimating adds one parameter, so some authors write the penalty as . That shifts every AIC by the same constant, so it doesn’t change which degree wins.
- Small samples. When is not large relative to , the bias-corrected is safer and penalizes high degrees harder. For the shark fin with dozens of curve points and a handful of control points, the plain AIC and will usually agree, but it’s worth checking on sparse data.
The function select_degree_aic works well when the data is noisy, because noise creates a floor on SSE that the penalty can eventually overcome, and the AIC minimum selects a sensible degree. For the shark-fin curve with points and Gaussian noise , the AIC minimum is , which is exactly the true degree.
When AIC misleads: the SSE floor problem
On clean, digitized data the story is different. The shark-fin CSV (SharkFinCurve.csv, points, no measurement noise) produces the following table when select_degree_aic sweeps :
| SSE | AIC | AIC | max resid | |||
|---|---|---|---|---|---|---|
| 2 | 2 | 0.636 | −406 | 908 | 0.987 | 0.205 |
| 3 | 4 | 0.310 | −463 | 851 | 0.994 | 0.142 |
| 4 | 6 | ≈ 0 | −1246 | 68 | 1.000 | 0.0025 |
| 5 | 8 | ≈ 0 | −1245 | 69 | 1.000 | 0.0024 |
| 6 | 10 | ≈ 0 | −1259 | 55 | 1.000 | 0.0021 |
| 7 | 12 | ≈ 0 | −1274 | 40 | 1.000 | 0.0024 |
| 8 | 14 | ≈ 0 | −1280 | 34 | 1.000 | 0.0019 |
| 9 | 16 | ≈ 0 | −1288 | 26 | 1.000 | 0.0019 |
| 10 | 18 | ≈ 0 | −1314* | 0 | 1.000 | 0.0018 |
Once the degree reaches 4, SSE drops to numerical zero and . The log-likelihood term saturates, and AIC keeps improving only because the penalty grows more slowly than the marginal gain from floating-point noise. The same failure occurs with and BIC. All three criteria prefer the maximum degree in the search range, wherever that happens to be set.
The real decision boundary is visible in the max residual column: a 58× drop between (0.142) and (0.0025), after which further improvement is less than 30% across six additional degrees. AIC can’t see this because it operates on SSE, which is already near zero. The geometric residual is what carries the signal.
Automatic degree selection: select_degree_robust
select_degree_robust in DegreeSelection.jl automates the elbow argument above. Its algorithm has three steps.
Step 1 — Sweep. Call fit_bezier_odr for every in , recording SSE, AIC, and the maximum geometric residual at each degree.
Step 2 — Elbow detection. For each consecutive pair of degrees, compute the improvement ratio
The elbow is the first where (default ). If the ratio is treated as , so a numerically exact fit always triggers the elbow. If no ratio exceeds which happens on noisy data where the residual declines smoothly, the function falls back to the AIC minimum, matching the behavior of select_degree_aic.
Step 3 — Plateau selection. Among all degrees where
return the smallest such .
function select_degree_robust(Q::Matrix{Float64};
m_min::Int = 2,
m_max::Int = 12,
τ::Float64 = 10.0,
ε::Float64 = 2.0,
tol::Float64 = 1e-10)
sweep = fit_sweep(Q, m_min, m_max, tol)
degrees = sort(collect(keys(sweep)))
m_elbow = _detect_elbow(sweep, τ)
if m_elbow === nothing
m_elbow = degrees[argmin([sweep[m].AIC for m in degrees])]
println("[select_degree_robust] No elbow found; " *
"falling back to AIC minimum at m=$m_elbow")
end
m_best = _plateau_select(sweep, m_elbow, ε)
println("[select_degree_robust] Elbow at m=$m_elbow. " *
"Selected m=$m_best (smallest in plateau). " *
"AIC=$(round(sweep[m_best].AIC; digits=2))")
# diagnostics Dict omitted for brevity — see DegreeSelection.jl
return m_best, sweep[m_best].P, sweep[m_best].t
endOn the shark-fin curve, the function prints:
[select_degree_robust] Elbow at m=4 (ratio=57.8). Selected m=4 (smallest in plateau). AIC=-1245.85The ratio 57.8 is the measured : the max residual fell by nearly 58× when the degree increased from 3 to 4.
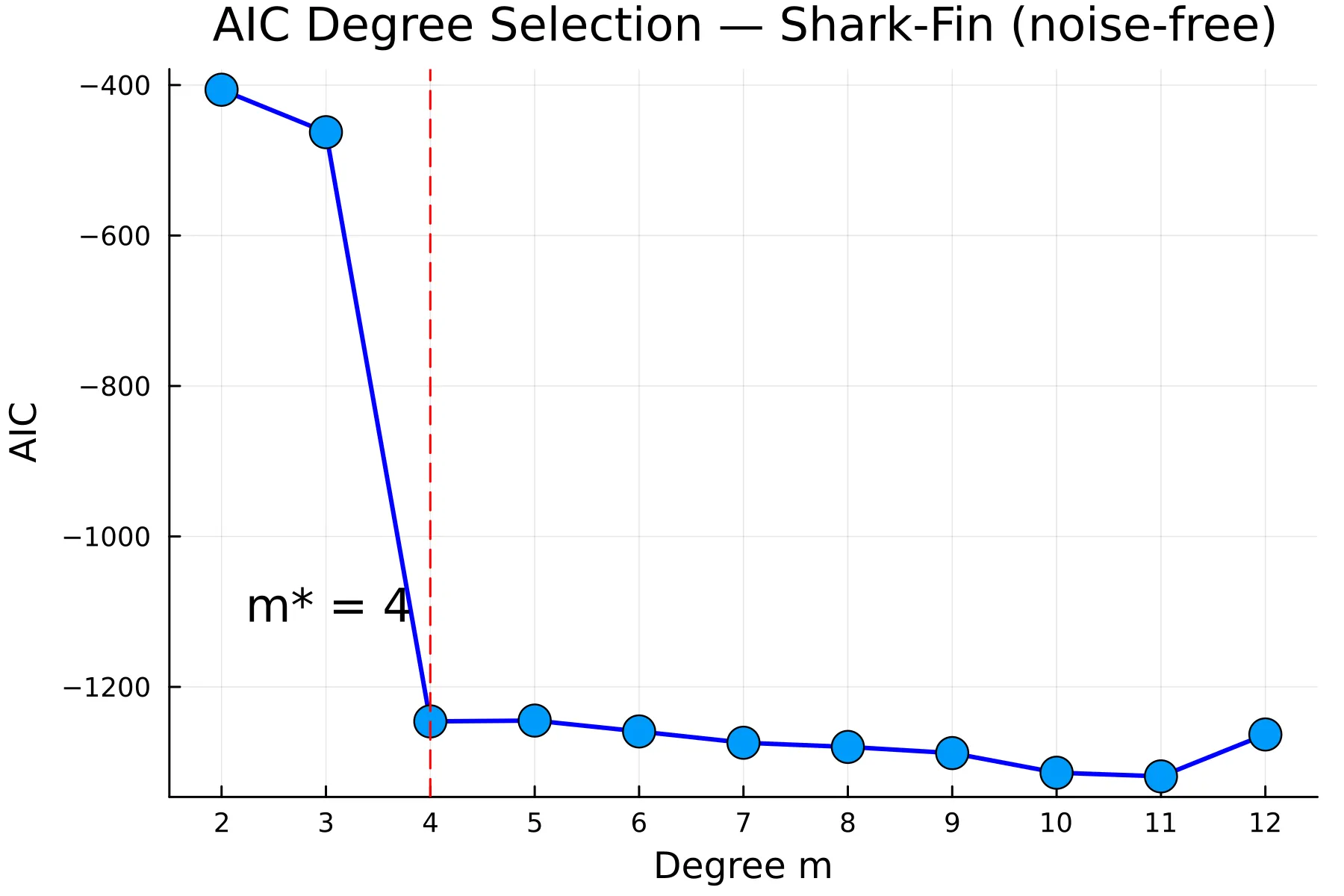
AIC vs. degree for the noise-free shark-fin data ().
The sharp drop between and is the elbow that select_degree_robust detects. AIC continues to improve above because SSE has already reached numerical zero, so the penalty no longer dominates. The dashed line marks the selected degree .
The Akaike Information Criterion isn’t the only model selection tool. The Bayesian Information Criterion
replaces the fixed penalty with , which grows with sample size and consistently favors lower degrees than AIC. A good overview of both is in Choosing the Best Model: A Friendly Guide to AIC and BIC. On the clean shark-fin data, BIC and both suffer the same SSE-floor failure as AIC, and all three prefer the maximum degree in the sweep range.
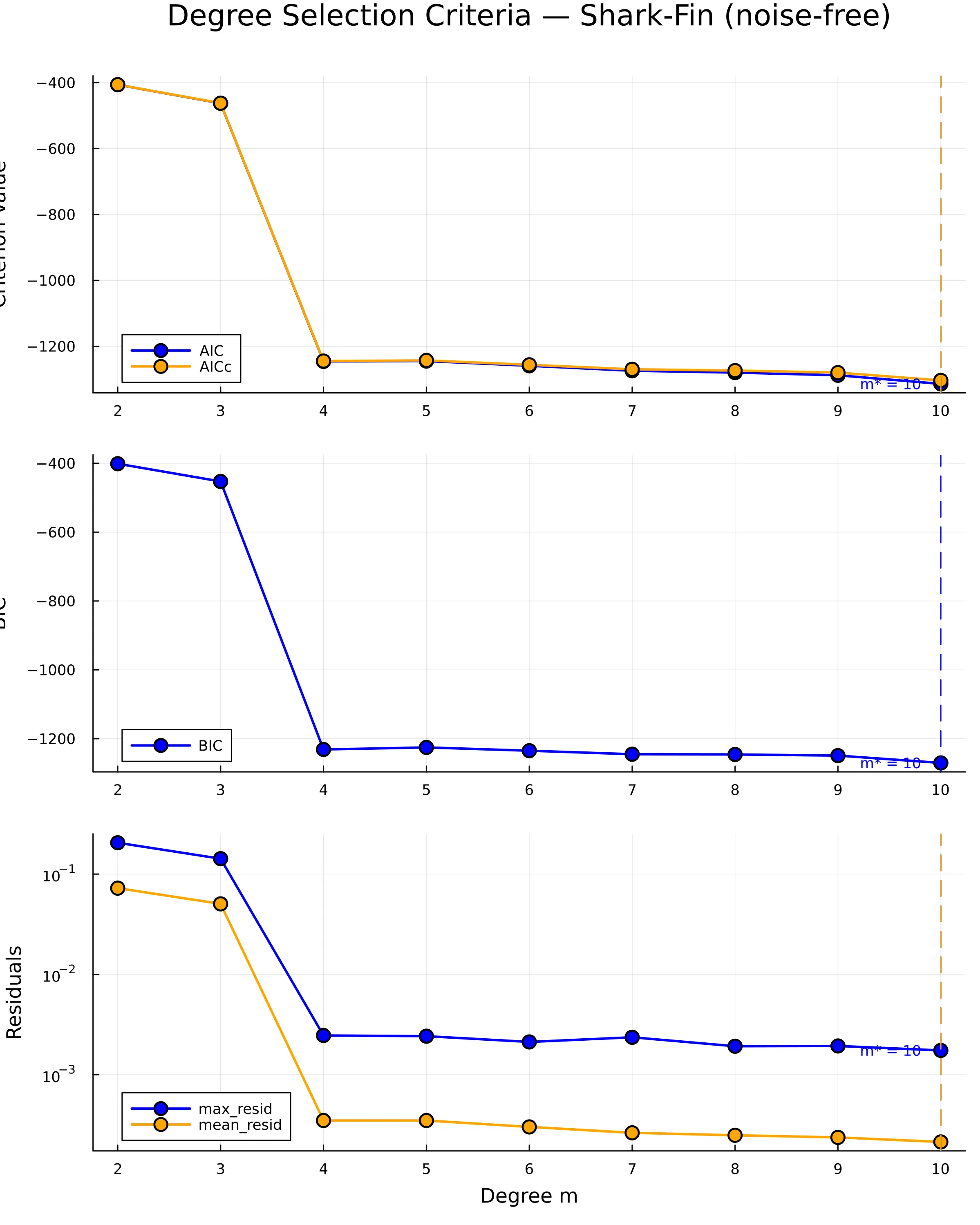
Comparison of AIC, , and BIC (top two panels) and geometric residuals (bottom panel) across degrees 2–10 for the noise-free shark-fin data.
All three information criteria continue improving past the elbow at because SSE is at numerical zero for . The residual panel (log scale) shows the true signal: a 58× drop at , with less than 30% further improvement across six additional degrees. The vertical gray line marks the elbow.
To summarize the selection strategy:
- Noisy data (, SSE declines smoothly): use
select_degree_aic. The AIC penalty will dominate once the degree exceeds the signal in the data, and the minimum is meaningful. - Clean or near-clean data (digitized curves, CAD traces, noise-free simulations): use
select_degree_robust. AIC will overfit; the geometric elbow will not. - When in doubt: call
select_degree_robustwith default parameters. On noisy data it falls back to the AIC minimum automatically, so it is strictly more general thanselect_degree_aic.
Monotone reparameterization
The ODR routine is free to move each wherever it lowers the distance, and nothing in the objective forces the to stay in order. Usually they do, but on a curve that doubles back on itself, two data points can be assigned values that are out of sequence. If you need a strictly increasing parameterization for resampling, arc-length work, or just tidiness monotone_reproject re-solves for point by point, holding each one to the right of its predecessor:
function monotone_reproject(Q::Matrix{Float64}, P::Matrix{Float64};
tol::Float64=1e-10)::Vector{Float64}
n = size(Q, 1)
t_proj = zeros(n)
t_proj[n] = 1.0
for i in 2:n-1
t_lo = t_proj[i-1]
dist2(t) = sum((bezier_eval([t], P)[1, :] .- Q[i, :]) .^ 2)
t_proj[i] = _golden_section(dist2, t_lo, 1.0; tol=tol)
end
return t_proj
endFor each interior point it minimizes the squared distance to the curve over the interval with a golden-section search, which guarantees the new can’t fall below . The control points are left untouched and only the parameterization changes so the SSE may increase slightly relative to the unconstrained ODR fit. Notice that this per-point closest-point search is exactly the geometric problem of the next section, solved numerically one point at a time. ODR was solving the same problem for all points jointly.
Note: The two sections that follow (“Finding the closest point by hand” and “Cubic and Quadratic Spline Interpolation”) are geometric background. None of it is needed to run the fit — ODR handles the closest-point problem automatically. These sections are here for readers who want to understand what the optimizer is minimizing, or who need to compute closest points independently of the fitting pipeline.
Finding the closest point by hand
Rather than trying to find the optimal vector, suppose we wanted to find the best values for the control point locations using the we have. The locations of the points in are determined by the positions of the control points , so the goal is to move the control points around until the difference between and is minimized. A couple of ways to minimize these distances are to minimize the sum of the errors, or to minimize the worst case, or maximum error. This is the manual version of the orthogonal distance that ODR minimizes automatically.
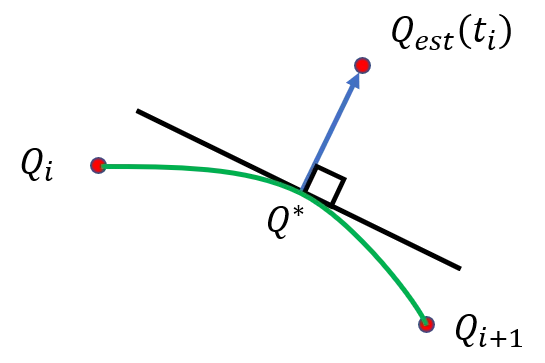
Perhaps the easiest way to find the closest point on the curve to an estimated point would be to draw straight lines between successive points in and then get the minimum distance between and the nearest line segment. This will be perpendicular to the line segment and passing through .
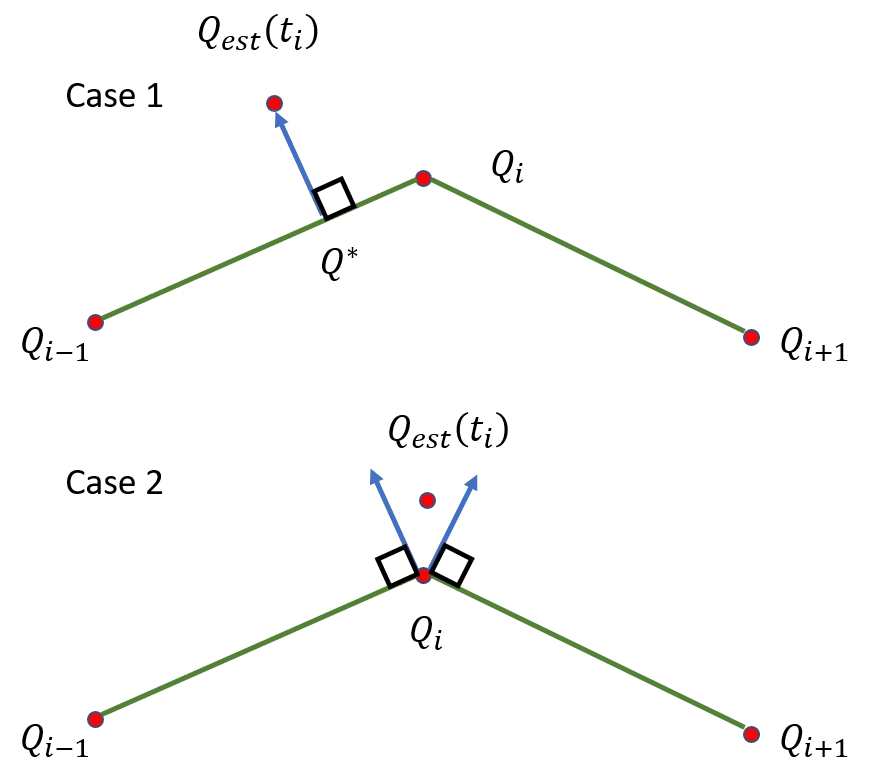
Linear interpolation of the parameterization .
This works well so long as can be reached by a perpendicular segment (Case 1). But as shown in Case 2, if is near node , and between the endpoint perpendiculars, the method fails. A sharper turn at leaves more room for an undefined condition, but in most cases, we’ll have lots of points along the length of , and the turns will be fairly shallow. If falls in the undefined region, the easiest solution would be to simply measure the distance between and .
To find in Case 1, lets parameterize the segment from to by where , so the segment becomes
If , then you’re at and if you’ve arrived at . The point will be at some value of where the vector is perpendicular to the vector , or equivalently, the dot product is zero,
which means
This works well if is between and as in Case 1. If it turns out that is outside the interval, check an adjacent interval. If in one interval and in an adjacent interval, then is in the undefined region of Case 2 and we can use as the minimum distance.
Continuity, Differentiability and
This section gives the definitions and a bit of explanation about the concepts of continuity, differentiability and curves. A complete understanding of these ideas isn’t necessary for the mathematics above, but could be a useful reference.
Continuity
A continuous function is pretty much what you’d expect - there are no gaps in the plot of the function. For a function to be continuous at a point , it has to satisfy three conditions:
- The function must exist at , that is exists.
- The limit of the function near must exist. For any small value of , there must be a finite value of .
- The limit of as must be . In other words, the value of the function near has to be the same on either side of . Another way to say this is that for some very small amount .
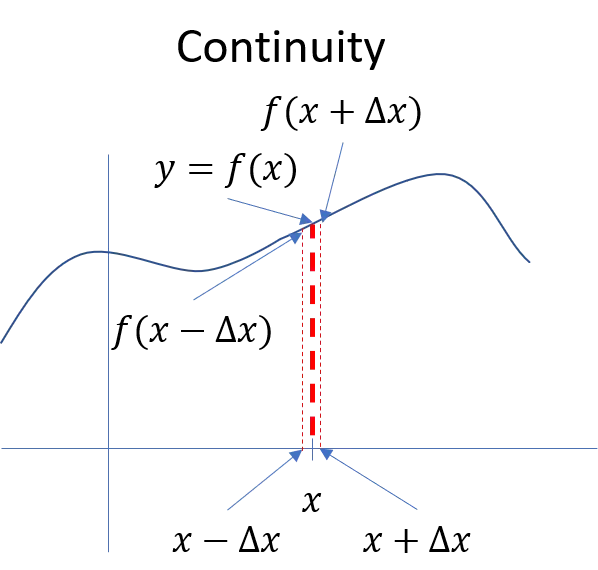
Mathematical definition of continuity.
In this picture, the ‘s are too big, so isn’t the same as , but the way we handle this problem is to take the limit as gets close to zero. If the three conditions above hold for very tiny values of , then is continuous at the point , and if they hold for all values of , then we say the function is continuous.
Here are a couple of examples of functions that are not continuous.
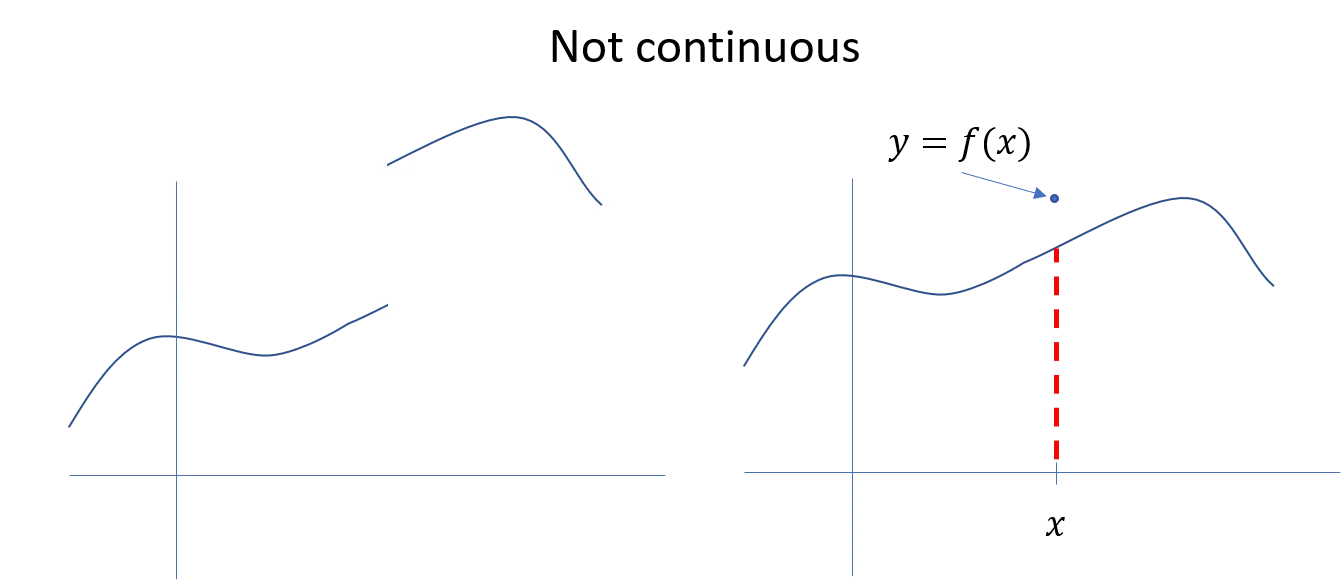
A discontinuous function.
The one on the left has a big jump, so it’s clearly not continuous. The one on the right looks continuous, but at , the value of isn’t the same as very nearby points, so it’s not continuous either. There’s a tiny hole in the function that you can’t see in the plot, but it makes the function discontinuous.
The absolute value function, is continuous even at because as you approach from either side, gets close to zero and the absolute value of zero is zero.
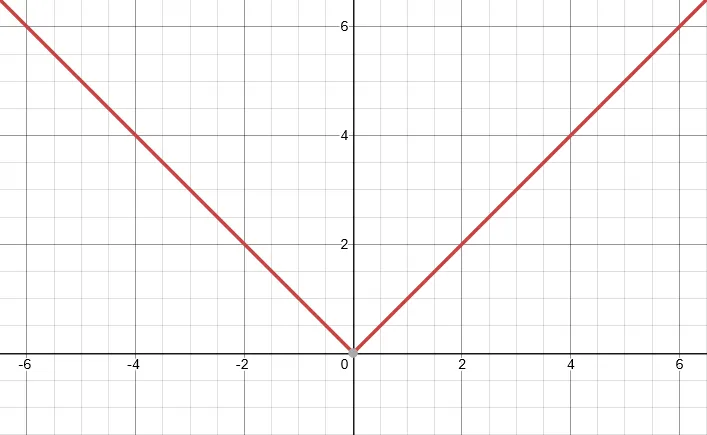
The absolute value function is continuous, but not differentiable at .
Slope and differentiability
You might remember that the slope of a line is defined as the change in values divided by the change in ,
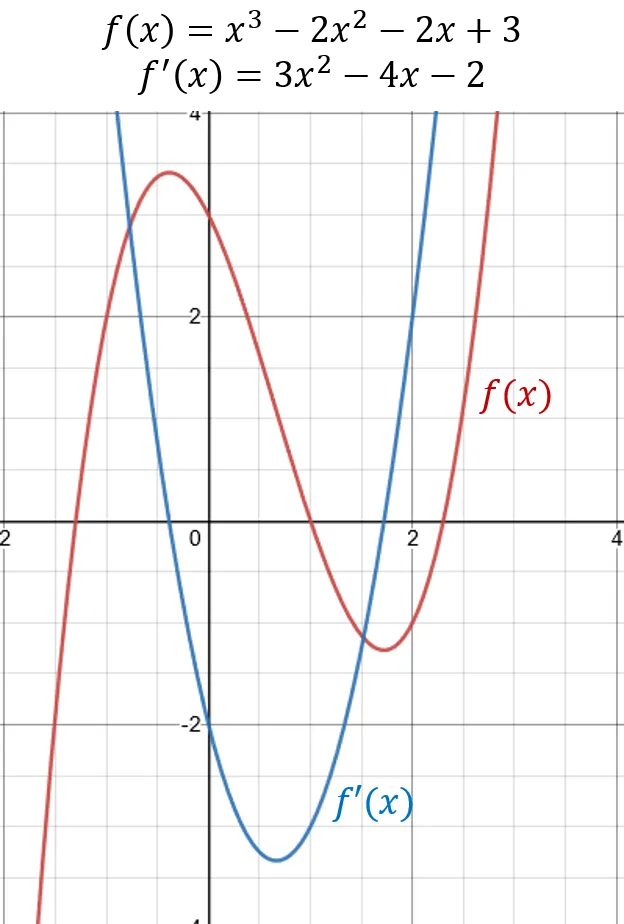
Looking at the left side of the absolute value function above, for , every time the value changes by one unit, the value changes by , so the slope . On the other side, , goes up by for every change , so the slope is . What is the slope for a function that curves all over the place? Something like this function ?
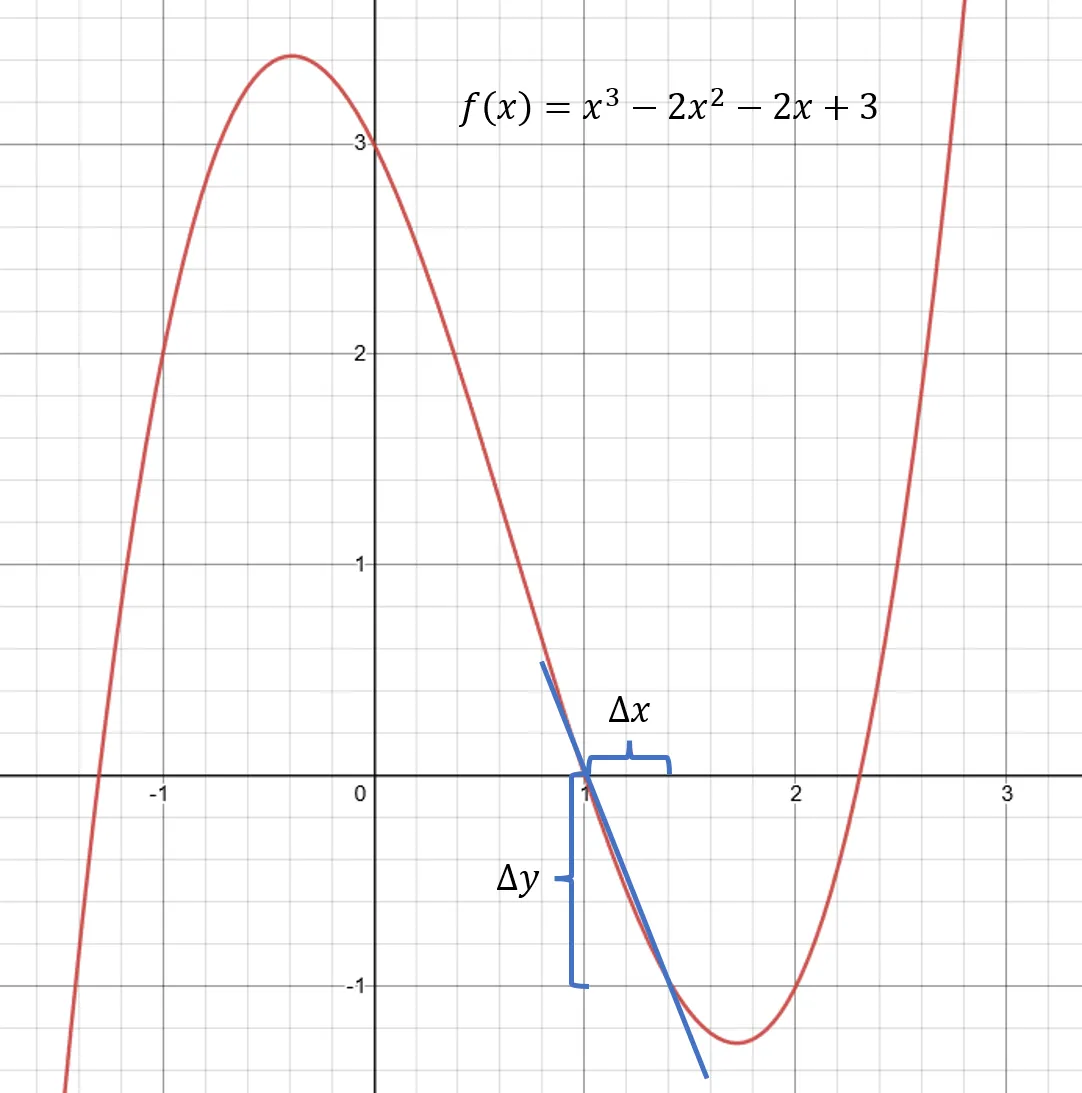
The cubic function .
Suppose we want to estimate the slope at . We could choose a small step and get the change in -values between the two points. At , . If we evaluate at we get . So, the slope of the line between these two points is
If we took a smaller step, , we find that which means that the slope is . Which is the right answer?
Let’s use a little algebra to find out. First, we need to calculate . Instead of working out all of the terms, we can enter each one into Wolfram Alpha. You should get this,
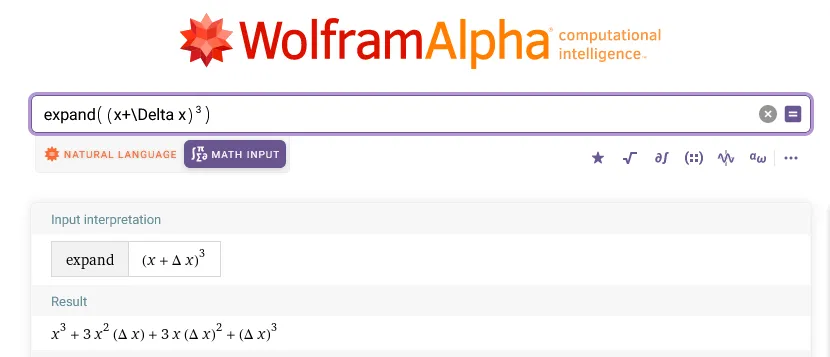
Expansion of terms in Wolfram Alpha.
Next, expand the second term to get . So, the expanded version of is
If we subtract from , that’s just , the change in height as we go from to . Since , then
Now, we can calculate the slope,
We still don’t know how big the step should be, but it seems like it should be as small as we can possibly make it. If we imagine that is so small that it’s practically zero, then the two terms and become nearly zero to the point that they can be safely ignored. Then the slope is
Notice that we didn’t select a value for before calculating the slope. What this means is that the equation for is valid for any , and instead of writing it as the slope something, it’s usually written as or more compactly where the apostrophe indicates this new function, the derivative of .
The derivative function.
Now we can calculate the slope of at any point exactly. For , , meaning that right there, the change in divided by the change in is . To make these plots, go to the Desmos calculator and enter the equations in the panel on the left side.
Input equations in Desmos.
curves
What was the point of all this discussion about continuity and differentiability? A curve is one that is continuous, and the first, second, and so on, up to th derivatives are also continuous. Since is a function, then we can take its derivative and get the second derivative function, and keep going to the th derivative function . If all of these are continuous functions, then the original function is called .
The absolute value function, is continuous, but the derivative is not continuous because it jumps from to at the origin (). So, is a curve meaning that the function is continuous, but any derivative has a discontinuity at zero.
We showed that has a derivative. You could check that both the function and its derivative are also continuous. Using the same method as before, it’s possible to show that the derivative of is , and the third derivative is . All of these functions are also continuous everywhere, so is at least a function. If you take it one more step, you’ll find that as is for any . These are pretty boring functions because for every , but they are continuous and differentiable. A function that can be differentiated repeatedly like this where all of the derivatives are continuous is called a function (“Cee infinity”).
In the post Curve Fitting with Julia we discussed the Weierstrass Approximation Theorem which says that any continuous function can be approximated with a polynomial. The absolute value function is continuous, so the theorem says that we can find a polynomial approximate. While it would be possible to approximate functions with a Bézier polynomial, going one level up to functions makes the approximation much easier.
Why is the fitted result ? Each Bernstein basis polynomial is a polynomial in , and a polynomial is infinitely differentiable everywhere. The Bézier curve is a linear combination of these polynomials, so it is also — in particular — with respect to . When viewed as a planar curve, both coordinates and are smooth, and the tangent direction varies continuously everywhere except potentially at or if the endpoint control points are coincident. For the curves we fit here, the endpoints are distinct, so the fitted Bézier is fully on .
Cubic and Quadratic Spline Interpolation
This section, like the last, is background: a more accurate way to find the closest point on the curve than straight-line segments. It’s the high-precision version of the distance ODR minimizes for us, kept here for readers who want to compute closest points themselves.
One way to approximate a curve is to use polynomials to fit each segment of the curve. In fact, many CAD (Computer aided design) programs use cubic splines to generate curves. A cubic spline requires four coefficients, and if you want a curve that loops around a bit, you might have to parameterize the curve as a function of which would take a cubic in both the and coordinates for a total of eight coefficients.
Many CAD programs allow you to draw smooth curves by generating cubic splines, but the process can slow down the computer because of the number of calculations required. Even so, we can use cubic interpolations to find the nearest point to the curve . By generating the interpolation once, the computational cost isn’t high, and then we can use some math to find the nearest point.
In Julia it’s easy to get a cubic interpolation of the points in the curve using the CubicSplineInterpolation function. Between each pair of curve points and , CubicSplineInterpolation will return a pair of parameterized cubic functions,
where for each segment. Suppose we have found a set of estimated curve points as above, and want to know the closest point to the original curve. The green curve is the cubic approximation, the black line is tangent at the closest point, and the blue arrow is the vector from to .
Quadratic interpolation of the curve points.
The tangent is just the derivative of ,
To simplify the notation a bit, let’s call the coordinates of . The closest point, has coordinates for some . To find the optimal value of , notice that the tangent line and the vector from and are perpendicular, so their dot product is zero,
or,
when . Expanding and collecting terms gives a quintic equation,
Finding the roots of 5th degree polynomials (or higher) is impossible analytically, and has to be done with numerical methods such as with the roots function. In this case, you would need to find the interval closest to and plug in the coefficients for the quintic to solve for the closest point. This needs to be done for each of the points in .
The first step is to fit cubic spline polynomials through the points in . All we need are the coefficients and , but what’s the right Julia code? One quick way to get the answer is to ask Google in AI mode. Here’s what I asked it:
Write a Julia function to fit a cubic spline interpolation through 2D points in array Q where Q is parameterized by the vector t,
t[0] = 0,t_i < t_{i+1},t[n] = 1. Return an nx4 array of coefficients for the cubic interpolating polynomials. It gave the following explanation and code,
To fit a parameterized cubic spline through a sequence of 2D points, we fit independent natural cubic splines to the and coordinates as functions of the parameter .
For each of the intervals between points, the interpolation polynomial takes the form:
Here is the complete, high-performance Julia implementation using standard linear algebra without external dependencies:
using LinearAlgebra
"""
fit_cubic_spline_2d(t::Vector{Float64}, Q::Matrix{Float64})
Fits a natural cubic spline through 2D points in `Q` (size N×2) parameterized by `t` (length N).
Returns a tuple (C_x, C_y) where each is an n×4 array containing the coefficients
[a, b, c, d] for the n = N-1 interval polynomials.
"""
function fit_cubic_spline_2d(t::Vector{Float64}, Q::Matrix{Float64})
N = length(t)
n = N - 1 # Number of intervals
# Extract X and Y coordinates
X = Q[:, 1]
Y = Q[:, 2]
# Calculate step sizes
h = diff(t)
# Solve for second derivatives (c coefficients) for X and Y
c_x = solve_spline_system(h, X, N, n)
c_y = solve_spline_system(h, Y, N, n)
# Pre-allocate coefficient matrices (nx4) for [a, b, c, d]
C_x = Matrix{Float64}(undef, n, 4)
C_y = Matrix{Float64}(undef, n, 4)
for i in 1:n
# X-coordinate coefficients
C_x[i, 1] = X[i] # a_i
C_x[i, 3] = c_x[i] # c_i
C_x[i, 2] = (X[i+1] - X[i])/h[i] - h[i]*(2*c_x[i] + c_x[i+1])/3 # b_i
C_x[i, 4] = (c_x[i+1] - c_x[i]) / (3 * h[i]) # d_i
# Y-coordinate coefficients
C_y[i, 1] = Y[i] # a_i
C_y[i, 3] = c_y[i] # c_i
C_y[i, 2] = (Y[i+1] - Y[i])/h[i] - h[i]*(2*c_y[i] + c_y[i+1])/3 # b_i
C_y[i, 4] = (c_y[i+1] - c_y[i]) / (3 * h[i]) # d_i
end
return C_x, C_y
end
# Helper function to solve the tridiagonal matrix system for natural cubic splines
function solve_spline_system(h::Vector{Float64}, coord::Vector{Float64}, N::Int, n::Int)
# Natural boundary conditions specify c[1] = 0 and c[end] = 0
# Constructing Tridiagonal system: A * c = B
dl = zeros(N-1) # Lower diagonal
d = ones(N) # Main diagonal
du = zeros(N-1) # Upper diagonal
B = zeros(N) # Right-hand side vector
for i in 2:n
dl[i-1] = h[i-1]
d[i] = 2 * (h[i-1] + h[i])
du[i] = h[i]
B[i] = 3 * ((coord[i+1] - coord[i])/h[i] - (coord[i] - coord[i-1])/h[i-1])
end
# Efficiently solve tridiagonal system using Julia's built-in Tridiagonal operator
return Tridiagonal(dl, d, du) \ B
endHow to use this function
# 1. Define parameterized time vector from t=0 to t=1
t = [0.0, 0.25, 0.6, 1.0]
# 2. Define N x 2 matrix of target points
Q = [
0.0 0.0; # Point 1
1.2 0.5; # Point 2
0.8 2.1; # Point 3
2.5 1.8 # Point 4
]
# 3. Fit the splines
coeffs_x, coeffs_y = fit_cubic_spline_2d(t, Q)
# coeffs_x is now a 3x4 Matrix containing:
# [a_1 b_1 c_1 d_1;
# a_2 b_2 c_2 d_2;
# a_3 b_3 c_3 d_3]
println("X Coefficients for Interval 1: ", coeffs_x[1, :])Technical highlights
- Zero Allocations System: Uses the
Tridiagonal(dl, d, du)type from Julia’sLinearAlgebrastandard library. This ensures the linear system is solved in time via Thomas’ algorithm instead of heavy full-matrix inversion. - Local Shift Formulation: Polynomials are structured around rather than absolute . This keeps calculations numerically stable and minimizes floating-point errors.
Since the fit only needs to be done once, it can be included with the function that estimates , and simplified to coeffs = CubicSplineInterpolation(t, Q).c. This generates a array of coefficients, one set for each of the rows of , and one each for the and terms. The CubicSplineInterpolation function returns a array rather than but we need to combine terms in the cubic equation above anyway. Make an array where each row contains the coefficients for the quintic polynomial above, and modify them with the terms containing and .
Instead of using cubic spline interpolations, you could fit each interval with a quadratic, or 2nd degree polynomial. If you do the same calculations as above but with quadratic fits, the resulting function will be a cubic polynomial.
In The Sum of the Sum of Some Numbers we discussed Tartaglia’s Depression which is a way to solve cubic equations by eliminating the term. The coefficients for the cubic are the terms in front of each which we can call , so for instance, .
Tartaglia wrote the solution to the cubic in the form of a poem. You can read about The Sordid Past of the Cubic Formula, and there’s a paper by Hongling Wang, Joseph Kearney, and Kendall Atkinson called Robust and Efficient Computation of the Closest Point on a Spline Curve that suggests using both a closed form solution like Tartaglia’s and an iterative method such as Newton’s.
The problem with using quadratic interpolation is that the splines aren’t smooth at the endpoints. It might not be noticeable if you plot the splines, but there will be sharp corners at the nodes. They won’t be as bad as using linear interpolation, but they’ll still be there. Cubic splines are designed to eliminate the corners at spline ends.
The goal is to find the value of for each that minimizes the distance to the original curve. Since we don’t have precise values for between the measured points, attempting to get very accurate error estimates could be a lot of unnecessary work. Besides, the measured points in are only as good as WebPlotDigitizer is able to read them from the input image. Depending on your application, you may want to consider using higher order fits.
Code for this article
This project provides an advanced toolkit for fitting Bézier curves to 2D datasets using Orthogonal Distance Regression (ODR) and robust automatic degree selection. It leverages ODRPACK to account for noise in both dimensions and provides sophisticated heuristics for selecting the optimal polynomial degree of the Bézier curve. All of the code is available on the Github repository Bezier-Polynomials.
Core ODR Engine & Math Foundation
These form the robust analytical and regression basis of the project:
BezierCurveFit.jl— Core mathematical routines and regression mechanics for fitting Bézier curves.bernstein_matrix(t, m)— Evaluates the Bernstein basis matrix.bernstein_deriv(t, m)— Evaluates the derivatives of the Bernstein polynomials.bezier_eval(t, P)— Evaluates a given Bézier curve from control points at parameters .beta_to_P(beta)— Reshapes the flat interleaved ODR parameter vector into a coordinate matrix.P_to_beta(P)— Flattens the control-point matrix into a 1D interleaved vector.bezier_fcn!(x, beta, y)— The in-place model evaluator passed intoOdrpack.bezier_jac_beta!(x, beta, jb)— Computes the analytical Jacobian w.r.t the control points.bezier_jac_x!(x, beta, jx)— Computes the analytical Jacobian w.r.t the parameter .chord_length_param(Q)— Provides an initial distribution based on cumulative Euclidean distance.init_control_points(Q, t, m)— Provides an initial via an endpoint-constrained least squares fit.fit_bezier_odr(Q, m; tol, reproject)— The master function that routes the setup into theOdrpackengine and recovers the fits.select_degree_aic(Q; m_min, m_max, tol)— Sweeps degrees and selects the optimal polynomial degree based on the Akaike Information Criterion._golden_section(f, a, b; tol)— Internal 1D minimizer used for strictly monotonic projection.monotone_reproject(Q, P; tol)— Post-processes fitted curves to guarantee sequential (monotonic) parameter assignments.
Older workflows, utilities
These files contain the older workflows, utility readers, and the refactored wrappers that route into the new ODR setup:
BezierFunctions.jlandBezierFunctions_v1.jl— Bezier related functions.readMeasPts(fName)— Reads spatial coordinate data () from a CSV.readCntrlPoints(fName)— Reads known/initial control points from a CSV.tStepFromQ(Q)— A legacy equivalent to calculating parameters from data points.bezfit_n(fName, n)— Refactored to ingest a CSV and immediately route the data throughfit_bezier_odr.bezfit_n1(Q, n)— Takes raw data arrays and routes them into the fitting mechanism.bezfit_q(Q, m)— Similar top-level data wrapper.bezval(P, nt, DispOn)/bezval_t(P, t)— Wrappers around basic Bézier evaluation and plotting.Qconstants(Q),coefMatA(t, nPts),genCoefMatrix(n)— Matrix construction helpers used by older deterministic least squares/polynomial pipelines.estimatedCurvePts(A, Q)/predictedCurveError(P, A, Q)— Legacy estimation metrics and residuals before ODR was implemented.nearestInterpPt(Q, B),nearestInterpPt_line_line(Q, P, k),t_fromRoots(Q, P, coefMat, t_prev)— The prior geometric/root-finding approaches to updating the variables (now superseded byodr_fit+monotone_reproject).fit_t_to_curve(Q, polydeg, DispOn)/fitParams(A, Q)— Legacy optimization interfaces.binomialVec(n)/Vandermonde(v, n)— Raw mathematical vector constructors.runAndPlot(P, Q)— Utility for rapid visualization of fits vs raw data.
Optimization
opt_t_vals(P, Q, t0)— Independent optimization script for determining best-fit variables given a rigid shape .optFun(c, n, i, p, q, t0)— Cost function helper used by the optimizer.
Application Layer
BezierHullFuncs.jl— Optimal fit of Bézier polynomials to arbitrary curves using the Akaike criterion.BezierHull(fPath, fName)— Analyzes bounding geometry and convex hulls relating to the curves.readXLSXtoStruct(fPath, XLfile)— Imports Excel-based coordinate structures.scale(v, sc)— Utility for dimension normalization.
Robust Degree Selection
DegreeSelection.jl— Robust automatic Bézier degree selection.select_degree_robust(Q; m_min, m_max, τ, ε, tol)— Public API. Selects the optimal Bézier degree via geometric residual-elbow detection. Falls back to the AIC minimum on noisy data where no elbow is found.fit_sweep(Q, m_min, m_max, tol)— Internal. Fits ODR curves across the degree range and returns a Dict of SSE, AIC, and residual diagnostics per degree._detect_elbow(sweep, τ)— Internal. Returns the first degree where the max-residual improvement ratio exceeds τ, ornothingif no elbow is found._plateau_select(sweep, m_elbow, ε)— Internal. Returns the smallest degree within ε of the elbow residual (Occam’s razor step).
Dependency Installation
install_deps.jl— Installs standard Julia dependencies and library packages.install_odrpack.jl— Specialized script for configuring and installing the underlyingOdrpackJulia wrapper required by the regression engine.
Visualization & Output Generators
compute_criteria.jl— Evaluates AIC, AICc, and BIC criterion for degree selection and generates a comparative table / figures.generate_robust_figures.jl— Generates a publication-ready AIC degree selection plot and the corresponding Bézier curve fit via theselect_degree_robustmethod.generate_figures.jl/generate_noisefree_figures.jl/regenerate_noisefree_figures.jl— General scripts for orchestrating sweeps, executing fits, and visualizing the ODR outputs versus data points.
Conclusion
What started as a shark fin drawn in GeoGebra turned into a complete pipeline for fitting smooth curves to real data. The key insight is that treating the parameter as a fixed quantity doesn’t work. Ordinary least squares with a guessed gives wrong control points, and the only cure is to let and the control points move together. The Orthogonal Distance Regression (ODR) algorithm handles it efficiently with analytic Jacobians and a trust-region solver.
The degree selection story has a similar lesson. Information criteria like AIC work well on noisy data because the penalty term can outrun a gradually declining SSE. On clean digitized data, SSE hits numerical zero too early, and all three criteria (AIC, AICc, BIC) chase marginal floating-point gains indefinitely. The geometric elbow in the max-residual profile is what actually finds the minimum, and select_degree_robust automates its detection with AIC as a fallback for the noisy case.
The tools built here — chord-length parameterization, endpoint-constrained warm start, ODR with analytic Jacobians, elbow-based degree selection, and monotone reparameterization — create a workflow pipeline that is useful well beyond shark fins. Some natural next steps: extending the approach to 3D space curves (the Bernstein basis is coordinate-independent), fitting closed loops (constrain and ), or computing curvature profiles along the fitted curve to detect inflection points.
Software
- Julia - The Julia Project as a whole is about bringing usable, scalable technical computing to a greater audience: allowing scientists and researchers to use computation more rapidly and effectively; letting businesses do harder and more interesting analyses more easily and cheaply.
- Geogebra - GeoGebra is dynamic mathematics software for all levels of education that brings together geometry, algebra, spreadsheets, graphing, statistics and calculus in one easy-to-use package.
- WebPlotDigitizer - WebPlotDigitizer is a computer vision assisted software that helps extract numerical data from images of a variety of data visualizations.
- WolframAlpha - WolframAlpha is an online knowledge engine developed by Wolfram Research that has been around since 2009. It is offered as an online service that answers queries by computing answers from externally sourced data.
- Notepad++ - Notepad++ is a free (as in “free speech” and also as in “free beer”) source code editor and Notepad replacement that supports several languages.
References
- C.F. Borges and T.A. Pastva, Total Least Squares Fitting of Bezier and B-Spline Curves to Ordered Data. Computer Aided Geometric Design. 2002.
- T.A. Pastva, Bezier Curve Fitting. Naval Postgraduate School, Monterey CA, Sept. 1998.
- C.F. Borges, Matlab code, borgespastva.m, Apr. 2014.
- Jani Data Diaries, Choosing the Best Model: A Friendly Guide to AIC and BIC, Medium, Nov 6, 2024.
- D.D. Marshall, Creating Exact Bezier Representations of CST Shapes, AIAA Session: Grid Generation and Effects of Grid Quality II, 2013.
- C-V. Muraru, On a Problem of Fitting Data Using Bézier Curves, Broad Research in Artificial Intelligence and Neuroscience, 2010.
- M.A. Zaman and S. Chowdhury, Modified Bézier Curves with Shape-Preserving Characteristics Using Differential Evolution Optimization Algorithm, Hindawi, 2013.
- D. Eberly, Least-Squares Fitting of Data with B-Spline Curves, Geometric Tools, 2020.
- D. Agarwal and P. Sahu, A Unified Approach for Airfoil Parameterization Using Bezier Curves, CAD and Applications, 2022.
- J. Xu et al., Accurate and Efficient Algorithm for the Closest Point on a Parametric Curve, International Conference on Computer Science and Software Engineering, 2008.
- H. Wang, J. Kearney, K. Atkinson, Robust and Efficient Computation of the Closest Point on a Spline Curve, 2002.
- R. Bergmann and P-Y. Gousenbourger, A Variational Model for Data Fitting on Manifolds by Minimizing the Acceleration of a Bézier Curve, 2018.
- A. Galvez and A. Iglesias, Firefly Algorithm for Bezier Curve Approximation, 13th International Conference on Computational Science and Its Applications, 2013.
- C. Loucera, A. Galvez and A. Iglesias, Simulated Annealing Algorithm for Bezier Curve Approximation, International Conference on Cyberworlds, 2014.
- J. Lifton, T. Liu and J. McBride, Non-linear least squares fitting of Bézier surfaces to unstructured point clouds, AIMS Press, 2021.
- J. Nocedal and S. Wright, Numerical Optimization, 2nd Ed., Springer, 2006.
- M. Bellucci, On the explicit representation of orthonormal Bernstein Polynomials, arXiv, 2014.
- A. Galvez, A. Iglesias, L. Cabellos, Tabu Search-Based Method for Bezier Curve Parameterization, International Journal of Software Engineering and Its Applications, 2013.
- L. Zhao et al., Parameter Optimization for Bezier Curve Fitting Based on Genetic Algorithm, Springer Nature, 2013.
- W. Wang and G. Wang, Bézier curves with shape parameter, Springer Nature, 2005.
- Q. Wu and F. Xia, Shape modification of Bézier curves by constrained optimization, Springer, 2005.
- J. Zwolak, P. Boggs and L. Watson, Algorithm 869: ODRPACK95: A weighted orthogonal distance regression code with bound constraints, ACM Transactions on Mathematical Software 33(4), 2007.
Image credits
- Mary McNamara (Los Angeles Times): The plot holes are “the whole point of movies like this: fabulous in-home commentary. Often accompanied by the consumption of many alcoholic beverages.”
- David Hinkley (New York Times): “Sharknado is an hour and a half of your life that you’ll never get back. And you won’t want to.”
- Kim Newman (Empire): “Cynical rubbish, with an attention-getting title and just enough footage of terrible CG sharks in a terrible CG tornado chomping on people to fill out a trailer suitable for attracting YouTube hits.”